Rails: How to Send and Receive Webhooks
This covers the joys and pains of a fully functional webhook system. Along the way I practice shower driven development to solve my problems.
There are two pieces to webhooks in Flipper Cloud – sending and receiving. Typically, a webhook system is only about the sending and receiving is left as an exercise for the customer.
But our situation is different. All feature flag data is stored locally in your application to keep reads blazing fast. In order to do this, we need to update your application data when things change in Cloud. This means we need a mechanism to sync.
Cloud supports two ways of syncing – polling (in development) and webhooks. But webhooks are the recommended way for syncing changes in Cloud to your application – especially in production. They ensure your application requests are never tied up polling for new data.
I didn't want every customer building their own webhook receiver and sync, so I knew I'd need to provide something automatic for them.
Before you can receive, you must send.
Sending Webhooks
I knew that webhooks would be tied to an environment. For those that are new here (👋) or need a refresher, Flipper Cloud is multi-environment in a few different ways.
The main relationships you need to know are:
- an
Organizationis the root. Organization has_many :projectsProject has_many :environments(e.g. QA, staging, production, etc.).Environment has_many :webhooks- And, finally,
Webhook has_many :webhook_responses
Managing the hooks
The boring, and perhaps more obvious, part of all this is the managing of webhooks. This looks like a fairly typical Rails CRUD section.
At of the time of writing, our webhooks table looks like this:
create_table "webhooks", force: :cascade do |t|
t.string "url"
t.integer "state", default: 0, null: false
t.integer "creator_id", null: false
t.integer "environment_id", null: false
t.datetime "created_at", null: false
t.datetime "updated_at", null: false
t.string "secret", limit: 50, null: false
t.text "description"
t.index ["environment_id"], name: "index_webhooks_on_environment_id"
end
We have a pretty standard Rails model wrapped around the table. It looks mostly like this:
require "securerandom"
class Webhook < ApplicationRecord
# Regex that webhook url must match.
URL_REGEX = URI.regexp(['http', 'https'])
# Hosts that we don't want to make requests to.
DENIED_HOSTS = %w(localhost 127.0.0.1).freeze
has_secure_token :secret
belongs_to :creator, class_name: "User"
belongs_to :environment
has_many :responses, class_name: "WebhookResponse", dependent: :destroy
delegate :project, to: :environment, allow_nil: true
delegate :organization, to: :project, allow_nil: true
enum state: {enabled: 0, deleted: 1, disabled: 2, disabled_by_admin: 3}
validates :url,
presence: true,
format: { with: URL_REGEX, allow_blank: true }
validates :creator_id, presence: true
validates :environment_id, presence: true
validate :url_host
scope :created, -> { where.not(state: :deleted) }
private
def url_host
return if url.blank?
uri = URI(url)
if DENIED_HOSTS.include?(uri.host)
errors.add(:url, "is invalid")
end
end
end
In the pics below, I show the UI for managing webhooks. In each of the screenshots, the UI is scoped to:
- Fewer & Faster (organization)
- Speaker Deck (project)
- Production (environment)
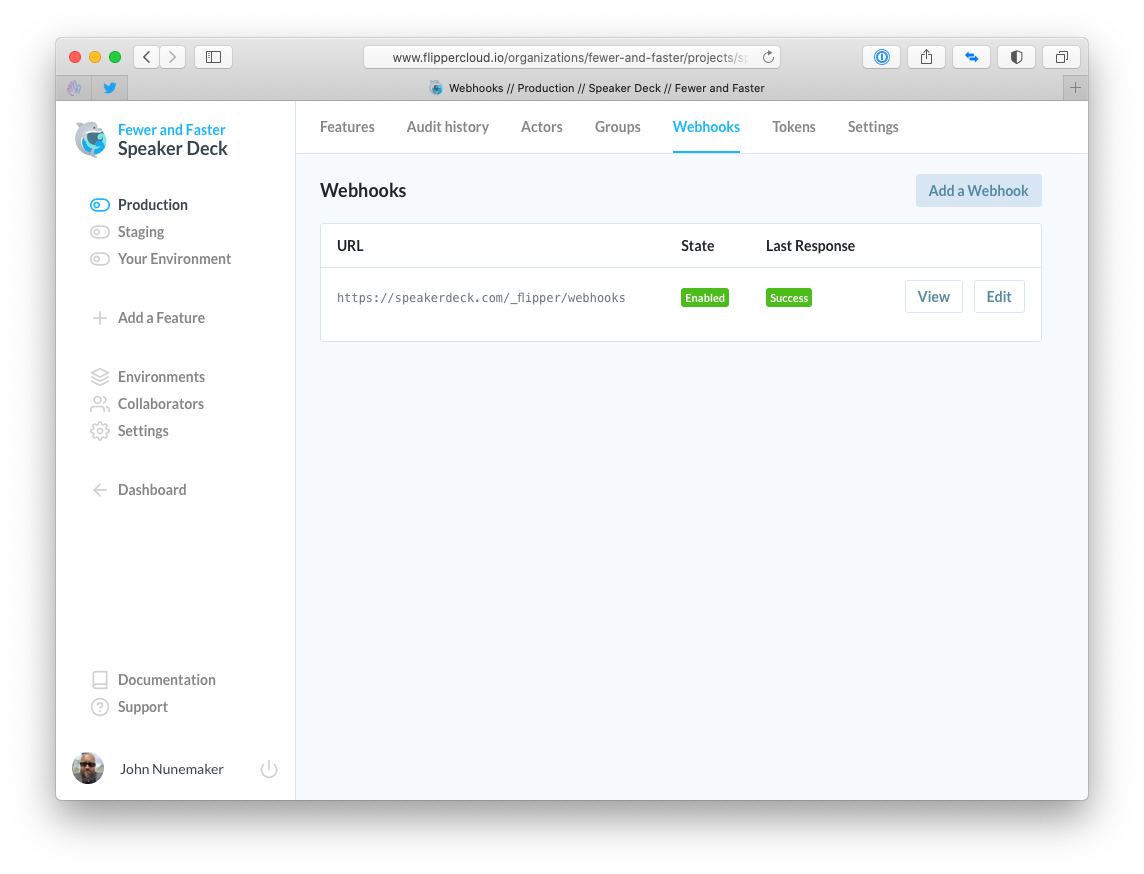
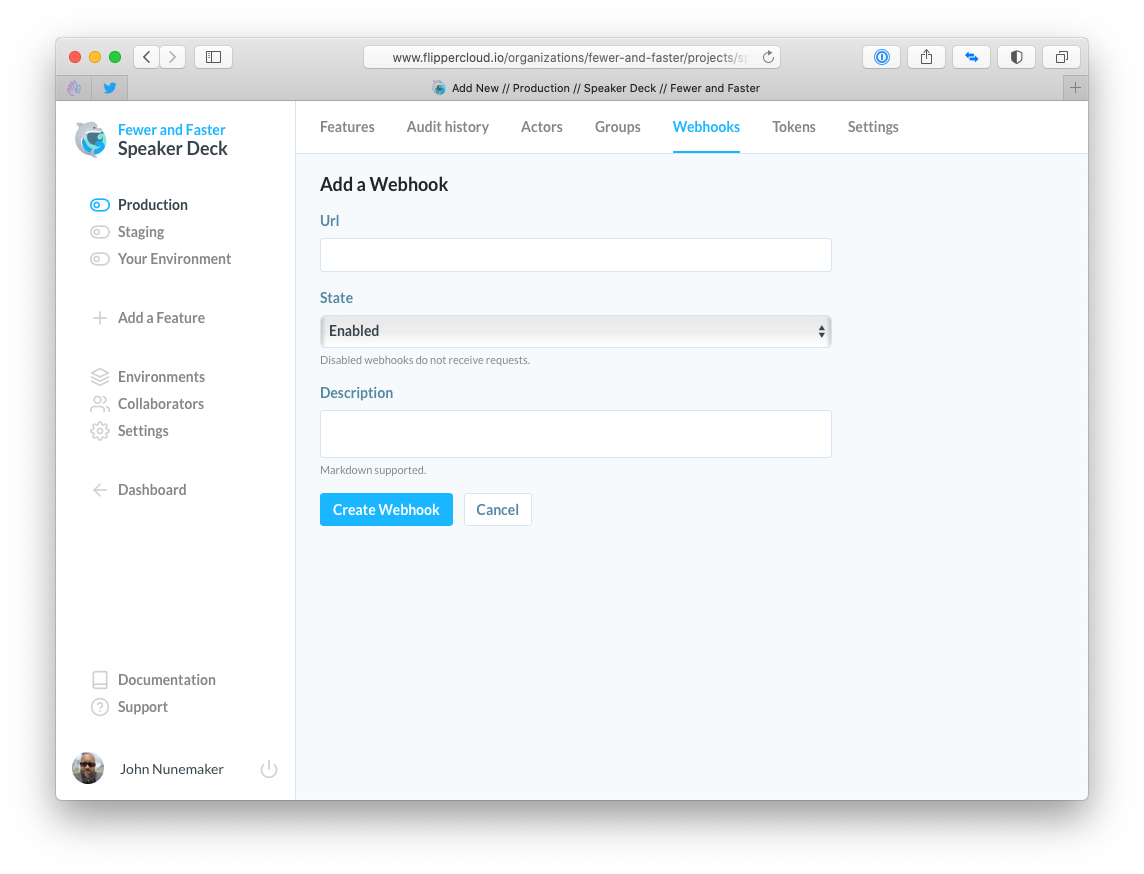
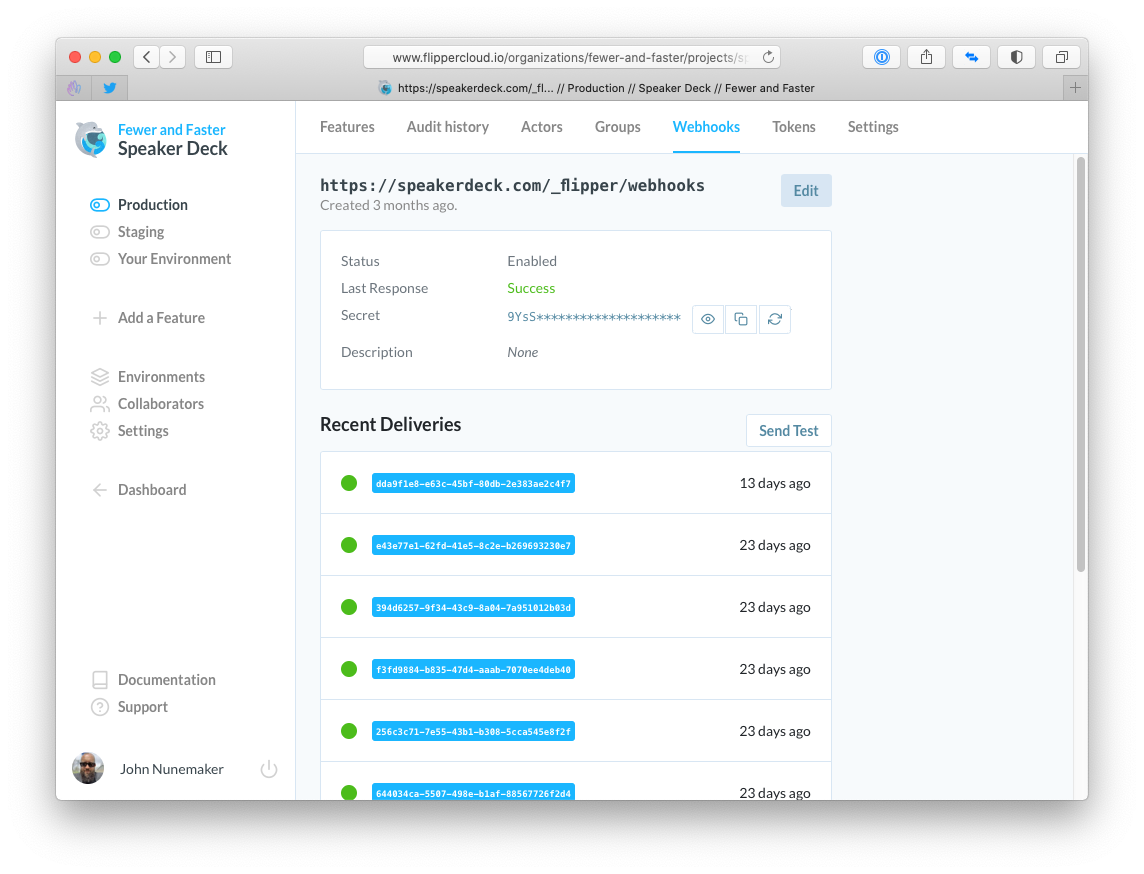
The controller for this area is, I would assume, a very stock Rails controller. If you recently read my post on reducing friction at the authorization layer, you'll notice some of the policy enforcement below.
class WebhooksController < ApplicationController
layout "environment"
before_action :find_organization_project_and_environment
before_action :check_for_enabled_webhooks
def index
authorize @environment, :view_webhooks?
@webhooks = @environment.webhooks.created.order(url: :asc).paginate(page: params[:page])
Webhook.preload_latest_responses(@webhooks)
end
def show
@webhook = @environment.webhooks.find(params[:id])
@webhook_responses = FindWebhookResponses.call(@webhook, page: params[:page])
end
def new
authorize @environment, :create_webhook?
@webhook = @environment.webhooks.build(creator: current_user)
end
def create
@webhook = CreateWebhook.call(
actor: current_user,
environment: @environment,
url: webhook_params[:url],
description: webhook_params[:description]
)
if @webhook.persisted?
redirect_to [@organization, @project, @environment, @webhook], notice: 'Webhook was successfully created.'
else
render :new
end
end
def edit
@webhook = @environment.webhooks.find(params[:id])
authorize @webhook, :update?
end
def update
@webhook = @environment.webhooks.find(params[:id])
authorize @webhook, :update?
if @webhook.update(webhook_params)
redirect_to [@organization, @project, @environment, @webhook], notice: 'Webhook was successfully updated.'
else
render :edit
end
end
def destroy
@webhook = @environment.webhooks.find(params[:id])
authorize @webhook, :destroy?
@webhook.deleted!
redirect_to [@organization, @project, @environment, :webhooks], notice: 'Webhook was successfully deleted.'
end
def send_test
@webhook = @environment.webhooks.find(params[:id])
webhook_policy = @webhook.policy(current_user)
if webhook_policy.send_test?
@webhook.sync
flash[:notice] = "Webhook test enqueued."
else
flash[:error] = webhook_policy.send_test.message
end
redirect_to [@organization, @project, @environment, @webhook]
end
def regenerate_secret
@webhook = @environment.webhooks.find(params[:id])
authorize @webhook, :regenerate_secret?
@webhook.regenerate_secret
redirect_to [@organization, @project, @environment, @webhook], notice: "Webhook secret regenerated. Be sure to update any place you were using the old secret with the new one."
end
private
def webhook_params
webhook_params = params.require(:webhook).permit(:url, :description, :state)
# If trying to use a state you don't have access to then remove the state.
if state = webhook_params[:state]
attempting_value_without_permission = !Webhook.state_select_valid_value?(current_user, state)
non_admin_attempting_to_enable_admin_disabled = @webhook && @webhook.disabled_by_admin? && !current_user.admin?
if attempting_value_without_permission || non_admin_attempting_to_enable_admin_disabled
webhook_params.delete(:state)
end
end
webhook_params
end
def find_organization_project_and_environment
@organization = current_organization
@project = @organization.projects.friendly.find(params[:project_id])
@environment = @project.environments.friendly.find(params[:environment_id])
authorize @environment, :show?
end
def check_for_enabled_webhooks
unauthorized unless Flipper.enabled?(:webhooks, @organization)
end
end
There is a bit of gnarly code around determining if the user can edit the state that I'd like to cleanup with a policy method, but I left it because I believe in showing you the warts and all.
If you noticed Webhook.preload_latest_responses and wondered about it, you can read my post on never querying the same thing more than once.
Protection with a feature flag
You may also notice that I check if the webhooks feature flag is enabled in a before_action. This allowed me to work on webhooks in production without customers using them before they were fully baked.
Could I remove that feature now that webhooks are fully released? Sure, I could. But it isn't hurting anything and does allow me to turn them off if I ever need to. For that reason, I've left the feature check in.
Firing the hooks
Now that people could manage webhooks, I needed to choose where and when a webhook request should actually be fired.
Thankfully, Flipper Cloud already has audit history for feature flags. When features are created, enabled or disabled in anyway we store a record of that. This audit history is built into the custom flipper adapter that cloud uses to manage feature flag data for an environment.
I already had a change method in the adapter that was creating the audit history. That seemed like the perfect place to also send webhooks. I created a new WebhookJob so I could enqueue a background job in the change method.
This is where it starts to get 🧃-y (aka juicy).
What could go wrong
My blessing and curse in life is fear of failure. It extends from my personal life (how should I invest this money) to my professional (how should I write this code).
I can't write a single line of code without mentally creating a matrix in my head of:
- how can this fail
- how likely is this to fail
- how bad would it be if it failed
- how easy is it to handle failure
- how can I remedy the failure
- and the list goes on...
Because of this curse, I immediately struggled with this job. We allow multiple webhooks per environment. I didn't want to enqueue N + 1 jobs where N is the number of webhooks for the environment. What if one of the jobs failed to enqueue?
Also, I like constants. No, not Ruby constants like User or BLAH_BLAH, but bits of code that do a constant number of network calls – aka anti-decay programming.
I wanted a single job enqueue at this code point, not a variable number of enqueues. So I enqueued the job with the environment and looped through the webhooks in the job like so:
class WebhookJob < ApplicationJob
queue_as :webhooks
def perform(environment)
environment.webhooks.enabled.find_each do |webhook|
SyncWebhook.call(webhook)
end
end
end
What if the webhook job performed, one webhook had a successful response and another a failed response? I would need to retry the failed one. I'd like to make a best effort to eventually get a hook request to that end point.
If I let the job system handle the retry, then each webhook that succeeded would receive another webhook. I could change this job and make it enqueue one job per webhook. At least this keeps the N+1 to the job system and out of any web request.
But what if there are 4 webhooks for this environment, 2 get enqueued and 2 don't because the job gets restarted for any number of reasons. When the job retries, it will enqueue 2 more jobs for the webhooks that already had jobs enqueued.
At least once
I don't need exactly once processing as it simply isn't worth the effort for this use case. I'm going for at least once, with a duplicate here and there being ok. It's just a sync request. If we have a few extra syncs, no biggie.
But even if I created a webhook response in the first two jobs, they'd have no way of knowing whether this is a new sync request or the previous one that was enqueued as a duplicate.
Shower driven development
In the 🚿 later that day, it hit me. I need an identifier. If I enqueue this job with a UUID and I store records of webhook requests with that UUID I can have good enough certainty to discard duplicates.
Enqueueing with the UUID is straightforward:
require "securerandom"
WebhookJob.perform_later(environment, SecureRandom.uuid)
The changes to the job are minor:
class WebhookJob < ApplicationJob
queue_as :webhooks
def perform(environment, uuid)
environment.webhooks.enabled.find_each do |webhook|
SyncWebhook.call(webhook, uuid: uuid)
end
end
end
This tiny little unique identifier makes it far more easy to make background jobs idempotent.
I added a delivered? method on Webhook.
class Webhook
has_many :responses, class_name: "WebhookResponse", dependent: :destroy
def delivered?(uuid)
responses.where(delivery_id: uuid).exists?
end
end
Note: I also have a unique index on webhook_id and delivery_id. This prevents the duplicate from being stored.
And I can then use that method in SyncWebhook to determine if we really need to sync or if we already have a response. Again, this isn't perfect as it has a read then write race, but it is good enough.
require "securerandom"
class SyncWebhook
def self.call(webhook, uuid: SecureRandom.uuid)
new(webhook, uuid: uuid).call
end
NOOP = GitHub::Result.new
def initialize(webhook, uuid: SecureRandom.uuid)
@webhook = webhook
@uuid = uuid
end
def call
return NOOP if webhook.delivered?(@uuid)
# do the sync
end
end
NOOP is just a sentinel value so I can tell if a hook was actually fired or not. I'd ignore it for now if I were you.
I can think of so many places this simple idea of enqueueing a job with an identifier would have been helpful. Not sure why it didn't occur to me before. Really any job that does more than one thing could benefit from this.
Time to party
I'd be cheating you if that was all I showed for the sending, so I'm going to leave the whole SyncWebhook class here for the curious. I'll add some comments to hopefully explain any parts that could cause confusion.
require "json" # to encode the body
require "httparty" # because I like to party
require "securerandom"
# something similar to ActiveSupport::MessageVerifier
# and Stripe's webhook verification. I added it
# separately to avoid needing to pull either of those
# as dependencies.
require "flipper/cloud/message_verifier"
class SyncWebhook
# convenience method at the class level
def self.call(webhook, uuid: SecureRandom.uuid)
new(webhook, uuid: uuid).call
end
# convenience reader methods
attr_reader :webhook
attr_reader :uuid
attr_reader :timestamp
# sentinel value for "nothing happened"
NOOP = GitHub::Result.new
# pretty stock initialize
def initialize(webhook, uuid: SecureRandom.uuid)
@webhook = webhook
@uuid = uuid
@timestamp = Time.now
end
# actually try to sync the hook
def call
# only sync if the policy is allowing it (aka they paying)
return NOOP unless webhook.policy.sync?
# no need to deliver if already delivered
return NOOP if webhook.delivered?(uuid)
# for tracking the duration
start = now
# its ok if this fails for now, we just want to wrap it up,
# but now that i look at it, this should rescue with another
# enqueue and a new uuid, maybe the old uuid as a parent uuid
GitHub::Result.new {
HTTParty.post(webhook.url, request_options)
}.map { |response|
# if the response succeeds, set the db attributes for code and headers
webhook_response_attributes[:status] = response.code
webhook_response_attributes[:headers] = response.headers
response
}.map { |response|
# we return the Flipper registered groups in the hook
# endpoint so this ensures they exist for the environment
create_groups(response.body) if response.code == 200
}.rescue { |error|
# if response fails then track the error in db,
# send to error tracking and return error
webhook_response_attributes.update({
error: {
class: error.class.name,
message: error.message[0..100],
backtrace: error.backtrace.first(5)
}
})
Raven.capture_exception(error)
GitHub::Result.error(error)
}
# store duration so we know slow hooks
webhook_response_attributes[:duration] = now - start
# try to create the webhook response in the database
GitHub::Result.new { webhook.responses.create!(webhook_response_attributes) }
end
private
def webhook_response_attributes
@webhook_response_attributes ||= {
request_url: webhook.url,
request_headers: request_headers,
delivery_id: uuid,
}
end
def now
Process.clock_gettime(Process::CLOCK_MONOTONIC, :millisecond)
end
# Heavily rescued method with best effort of creating the groups in the
# response body.
#
# This is very defensive as people can setup webhooks to anywhere and return
# any response body they want.
#
# Returns GitHub::Result.
def create_groups(response_body)
GitHub::Result.new {
JSON.parse(response_body)
}.map { |data|
if groups = data["groups"]
if groups.is_a?(Array)
registered_groups = groups.map { |row| row.is_a?(Hash) ? row["name"] : nil }.compact.uniq
RegisterAppGroups.call(webhook.environment, registered_groups)
end
end
}.rescue { |exception|
Raven.capture_exception(exception)
GitHub::Result.error(exception)
}
end
# this and the next few methods just set some
# reasonable timeouts, we don't want to sit here
# forever waiting on endpoints
def read_timeout
Integer(ENV["WEBHOOK_READ_TIMEOUT"].presence || 10)
end
def open_timeout
Integer(ENV["WEBHOOK_OPEN_TIMEOUT"].presence || 10)
end
def connect_timeout
Integer(ENV["WEBHOOK_CONNECT_TIMEOUT"].presence || 10)
end
def message_verifier
@message_verifier ||= Flipper::Cloud::MessageVerifier.new(secret: webhook.secret)
end
def signature
@signature ||= message_verifier.generate(request_body, timestamp)
end
def header
@header ||= message_verifier.header(signature, timestamp)
end
def request_headers
@request_headers ||= {
"Content-Type" => "application/json",
"Flipper-Cloud-Signature" => header,
}
end
# sync!
def request_body
@request_body ||= JSON.generate({
"environment_id" => webhook.environment_id,
"webhook_id" => webhook.id,
"delivery_id" => uuid,
"action" => "sync",
})
end
# add all the timeouts and details
def request_options
@request_options ||= {
body: request_body,
headers: request_headers,
read_timeout: read_timeout,
open_timeout: open_timeout,
connect_timeout: connect_timeout,
}
end
end
I think a case could be made to break this up into a few smaller classes (like all the http stuff). But my new life theme is good enough for now.
For more on why I'm using GitHub::Result all over the place, check out my resilience for ruby post. Also, I've previously written about the RegisterAppGroups class in my post covering rails insert_all and upsert_all.
Now that sending hooks was working, it was time to add receiving.
Receiving Webhooks
The receiving end of webhooks is all public in OSS flipper. But I'll cover it here for thoroughness sake. Many people these days just create Rails engines. I'd love to only do that. But doing only that means you leave out Sinatra, Hanami, Roda and friends.
I'm not one to leave anyone out and we have a standard for stuff like this – Rack. My typical route is instead to create a middleware that is used by Rack apps that get mounted in Rails routes or URL mapped in rackup files for the rest.
This makes it so everything built on Rack can Just Work™. And you can still add a Rails engine to mount the Rack app for automatic Rails support.
The middleware
The middleware for Flipper Cloud receives a webhook request (from Cloud), validates the signature, and performs a sync. It also returns the groups as I mentioned above, so we can keep those in sync for you. That's it.
require "flipper/cloud/message_verifier"
module Flipper
module Cloud
class Middleware
# Internal: The path to match for webhook requests.
WEBHOOK_PATH = %r{\A/webhooks\/?\Z}
# Internal: The root path to match for requests.
ROOT_PATH = %r{\A/\Z}
def initialize(app, options = {})
@app = app
@env_key = options.fetch(:env_key, 'flipper')
end
def call(env)
dup.call!(env)
end
def call!(env)
request = Rack::Request.new(env)
# backwards compatible stuff to make / and /webhooks work.
if request.post? && (request.path_info.match(ROOT_PATH) || request.path_info.match(WEBHOOK_PATH))
status = 200
headers = {
"Content-Type" => "application/json",
}
body = "{}"
payload = request.body.read
signature = request.env["HTTP_FLIPPER_CLOUD_SIGNATURE"]
flipper = env.fetch(@env_key)
begin
message_verifier = MessageVerifier.new(secret: flipper.sync_secret)
if message_verifier.verify(payload, signature)
# message is valid so let's do a sync
begin
# sync
flipper.sync
# return the groups in the response so cloud can pull them
body = JSON.generate({
groups: Flipper.group_names.map { |name| {name: name}}
})
rescue Flipper::Adapters::Http::Error => error
# if we received an error, check if payment is
# issue or something else
status = error.response.code.to_i == 402 ? 402 : 500
headers["Flipper-Cloud-Response-Error-Class"] = error.class.name
headers["Flipper-Cloud-Response-Error-Message"] = error.message
rescue => error
status = 500
headers["Flipper-Cloud-Response-Error-Class"] = error.class.name
headers["Flipper-Cloud-Response-Error-Message"] = error.message
end
end
rescue MessageVerifier::InvalidSignature
status = 400
end
[status, headers, [body]]
else
@app.call(env)
end
end
end
end
end
Not the prettiest of code. But as I age, I'd like to think that I'm a little better at letting working code that isn't the cleanest sneak into production. Reality is the world runs on dirty code and that middleware is probably in the top 1% of beautiful code despite its length.
The Rack app
Cloud has an app method for building the Rack app that you can then easily mount in your routes (for Rails) or url map in your rackup (for alternative frameworks).
module Flipper
module Cloud
def self.app(flipper = nil, options = {})
env_key = options.fetch(:env_key, 'flipper')
memoizer_options = options.fetch(:memoizer_options, {})
app = ->(_) { [404, { 'Content-Type'.freeze => 'application/json'.freeze }, ['{}'.freeze]] }
builder = Rack::Builder.new
yield builder if block_given?
builder.use Flipper::Middleware::SetupEnv, flipper, env_key: env_key
builder.use Flipper::Middleware::Memoizer, memoizer_options.merge(env_key: env_key)
builder.use Flipper::Cloud::Middleware, env_key: env_key
builder.run app
klass = self
builder.define_singleton_method(:inspect) { klass.inspect } # pretty rake routes output
builder
end
end
end
The app method is mostly boring – just building up a Rack::Builder instance. But you can see on line 12 where it uses the middleware.
You can then use it by mounting it in your Rails routes.
Rails.application.routes.draw do
mount Flipper::Cloud.app, at: "_flipper"
end
This adds an endpoint for your app at yourapp.com/_flipper (or wherever you mounted it).
Wrap Up
So there you have it. This post covered:
- managing webhooks
- finding the point in your code where you'll need to send the webhook
- how to party when actually sending the webhook
- how to receive the webhook on the other side
This is definitely a first iteration and will harden over time as all good production code does. But so far it has been working great. Nearly all of our customers are using hooks and we haven't had any problems to date.
Welp. That was another long one – a common theme here of late. But I hope you enjoyed it and maybe learned a little something. It took me around 3+ hours to write.
If you did enjoy or learn anything, you should probably check out Flipper Cloud. Sign up, kick the tires and let me know what you think. I crave feedback.
P.S. It is worth noting that I don't yet have backoff in retries or automatic disabling of failing hooks or all the other things that would be good. As I need and create these systems, I'll do my best to write them up as well.
P.P.S. If you'd like to see the functioning of this system in production from end to end, check out this one minute video.