Feature Flags: Not Just for Big Teams or Big Features
The query, cache, code, feature flag, graph and point: control your code, even the tiny bits.
As you may recall, I recently sold SpeakerDeck. The buyer is a friend so I'm still happy to help when I can. Recently, there was a performance problem that popped up. So I jumped in to fix it as any nerd-sniped programmer would.
As you might expect (if you thought about it), the most popular Rails route (by far) in Speaker Deck is viewing a talk. When viewing a talk, Speaker Deck also shows related talks.
First, related talks from the owner of the talk being viewed are shown. Then, if the talk is categorized, there is a random smattering of recent talks in the same category.
There be the dragons. 🐉
The Query
The related talks for a category query looked something like this (hint: its not real pretty):
Talk.published.sorted.for_category(talk.category).
where('talks.owner_id <> ?', talk.owner_id).
where('talks.id <> ?', talk.id).
where("views_count > ?", ENV.fetch("RELATED_CATEGORY_VIEWS_MINIMUM", 100).to_i).
limit(ENV.fetch("RELATED_CATEGORY_LIMIT", 100).to_i).
load.
shuffle.
first(ENV.fetch("RELATED_CATEGORY_COUNT", 12).to_i)
The ENV vars are just to make it easier to tweak without changing the code. It's easier to change an ENV var than make a branch, deploy, etc.
In English
The query is doing this:
- filter out private/deleted/etc talks (
published) - order by recent (
sorted) - filter to talks in the same category as the talk being viewed (
for_category) - filter out the talk being viewed (because they're already looking at it)
- filter out any talks by the same owner as the talk being viewed (since those are probably already shown)
- filter out any talks with fewer than 100-ish views
- only pull 100 across the wire (
limit, this is enough to show variety without making it slow by pulling too much data) - shuffle (so different decks show on each page load)
- show up to 12
I've definitely seen worse queries. But over time this query has gotten slower (it's not a great example of anti-decay programming).
The primary cause of slowness was the view_count filter. Prior to that addition, it was pretty snappy. But the view_count filter is valuable because it removes a lot of less valuable/interesting decks.
The Cache
I could have just come up with a new database index to help speed it up. But it likely would have still ended up regressing over time. This (expensive to compute and rarely changes) is actually a great example of when to reach for caching.
This data changes a few times an hour. But there is absolutely no problem with it being a little stale. No one will notice or care.
De-personalize
The first step to caching it was to remove the personalization (e.g. customization based on talk being viewed and user viewing talk).
Whenever possible, I avoid caching based on the current user (and definitely the current user + another object like a talk), as that won't save me much utilization (cold cache for each new user). And it would dramatically increase the size of the cache (M * N where M is talk and N is user).
So first I moved the server side filters of "not this talk" or "any talk by same owner" to the client side.
Moving these from server side to client side meant that I could safely cache it once for all users instead of per talk or user or (even worse) talk + user (aka M * N).
The Code
The resulting Ruby code looked something like this:
class RelatedTalks < Struct.new(:talk, :current_user)
# [ snipped for brevity... ]
def by_category
@by_category ||= begin
if talk.category
by_category_cached.reject { |category_talk|
category_talk.owner_id == talk.owner_id || category_talk.id == talk.id
}.shuffle.first(related_category_count)
else
[]
end
end
end
private
def by_category_cached
key = [
"related_talks_by_category",
talk.category.slug,
related_category_views_minimum,
related_category_limit,
]
Rails.cache.fetch(key.join("/"), expires_in: 60.minutes) do
by_category_fresh
end
end
def by_category_fresh
Talk.published.sorted.for_category(talk.category).
where("views_count > ?", related_category_views_minimum).
limit(related_category_limit).
load
end
def related_category_views_minimum
ENV.fetch("RELATED_CATEGORY_VIEWS_MINIMUM", 100).to_i
end
def related_category_limit
ENV.fetch("RELATED_CATEGORY_LIMIT", 100).to_i
end
def related_category_count
ENV.fetch("RELATED_CATEGORY_COUNT", 12).to_i
end
end
I often split out cached and fresh methods. I'm not sure when or where I started doing this. But it just feels easier to scan and allows for bypassing the cache by using the fresh method.
I certainly could have branch shipped this or gone a bit more cowboy and merged it into master and shipped it. But I HATE outages.
The Feature Flag
The most important thing to me is mean time to resolution (MTTR).
I want to (nearly) instantly rollback any changes instead of waiting minutes or longer for a rollback to happen. That's why I dropped a feature flag in.
Control Your Code
The change was minor. But the increase in control was substantial.
The only change below is an if/else flipper check to see if caching is enabled or not.
class RelatedTalks < Struct.new(:talk, :current_user)
# [ snipped for brevity... ]
def by_category
@by_category ||= begin
if talk.category
category_talks = if Flipper.enabled?(:related_talks_by_category_caching, current_user)
by_category_cached
else
by_category_fresh
end
category_talks.reject { |category_talk|
category_talk.owner_id == talk.owner_id || category_talk.id == talk.id
}.shuffle.first(related_category_count)
else
[]
end
end
end
# [ snipped for brevity... ]
end
Safety First
This tiny change meant that I could ship it to production with backwards compatibility.
I could deploy, enable the feature for me alone and ensure that it worked (you know, before shipping it to everyone and possibly causing an outage).
And that is exactly what I did. I enabled the feature for me and checked the rack mini profiler output. Everything looked good. 💥
I clicked enable in Flipper Cloud and instantly performance improved for the entire site. But don't trust me, trust my graphs.
The Graph
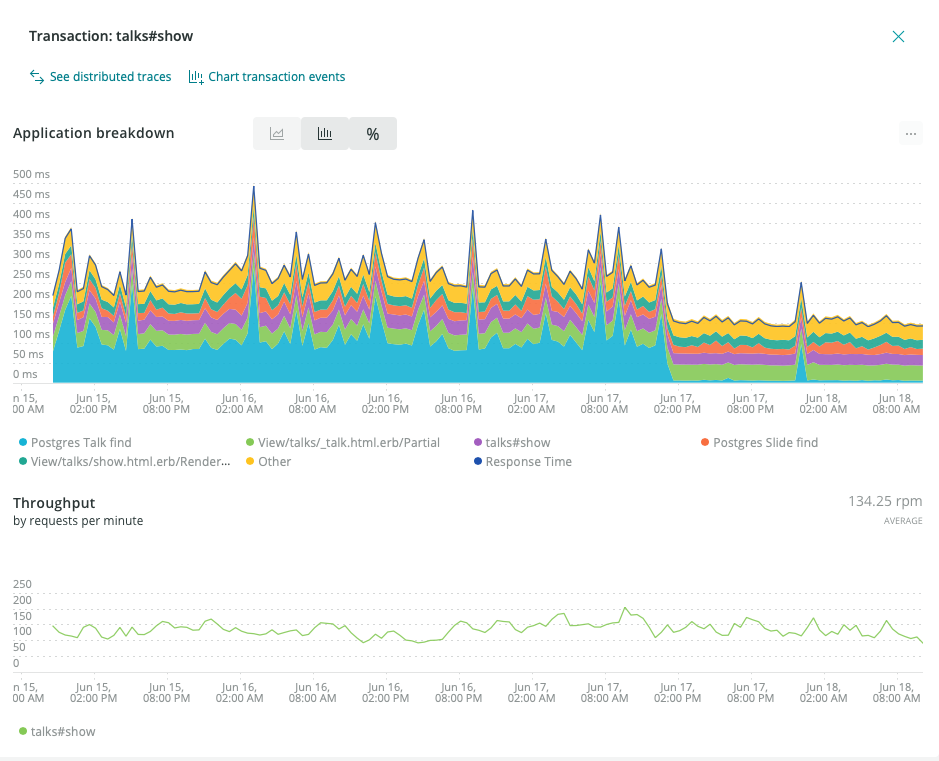
It's pretty obvious when the flipper feature was enabled (even my mom can tell and she's not a programmer; Hi Mom! She's a subscriber and reads every post even when it's all gobbledygook to her like this one). The blue in the graph above goes to nothing. Zilch. Nada.
This is what I call a drop off graph (and it's one of the things I live for).
It's the kind of graph I store in a folder named "Dexter" because performance problems were killed 🩸 and I want to remember it.
🩸 I mean yes, I have a folder named "Dexter" where I collect 📉 app perf improvements I've helped with.
— John Nunemaker (@jnunemaker) January 26, 2021
That's not weird. Everyone does, right?
And sometimes you too open the vent and 👀 at them for a bit. You know, to remember the good days... pic.twitter.com/HD1F3FRSPM
The Point
Again, just a reminder. In this instance, I'm a team of one. I reviewed my own pull request. Feature flags aren't just for large teams.
Along the same lines, this wasn't a huge new feature. This was a tiny code change (< 50ish lines of code). But it could have made (and did make) a large impact.
Putting changes like this behind a feature flag mean that I can control the blast radius if things go wrong and rollback instantly (button click verse re-deploying code for several minutes).
That's the point. Feature flags are control. And control is gives you confidence to move faster.