Anti-Decay Programming
de•cay noun - the state or process of rotting or decomposition.
Let us kick off the new year with a lovely post on decay. All systems decay. Even when you continually work on improving the system, it decays. That said, in my experience, not all decay is equal with regards to how it affects the system.
I am sure others have worked at larger scale than me and know even more timeless anti-decay techniques, but I think the two principles I am going to discuss below will help most people out there fighting the good fight.
Avoid Network Calls
Apps that are overly chatty with the network are the fastest to decay. You may think the first step is to make sure that you are making efficient use of network calls to fetch the data for the page. I would go a farther and first ask what data (and thus network calls) can I remove from the page, yet retain the usefulness for customers. I think often times we include data on the page because it is interesting, as opposed to useful.
Once you’ve removed any data that is “interesting”, ensure that you are efficiently loading the data in bulk/batches whenever possible (ie: avoid N+1’s, etc.). I usually aim for 5-10 network calls max on a page. This is not always possible, but serves as a good goal. If you have great infrastructure, you can get away with far more, but always remember to avoid network calls.
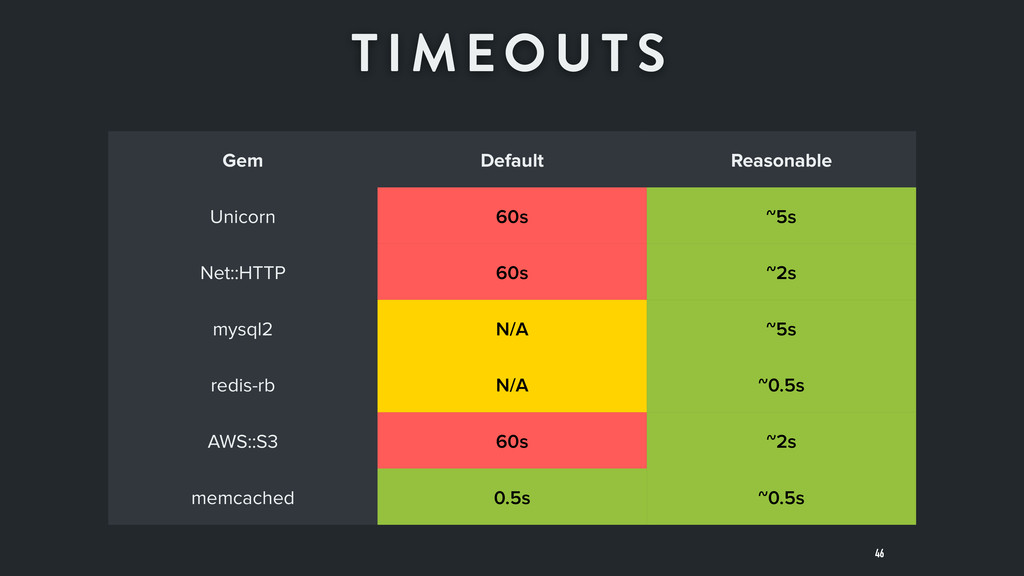
Another relatively easy step around network calls is to ensure you have timeouts. Most client libraries have lower level connect and read timeouts (see the ultimate guide to timeouts for ruby examples). Use them. Set them as low as you can. @sirupsen has listed some good defaults in a talk on SpeakerDeck (full presentation, slide image).
{kind=link}
Any network call that does not need to happen in a web request should be shipped to a message queue/processing system. Also, anything that cannot be bounded should be backgrounded and the web interface should work around that (polling, live updates, whatever). Basically, you never want to tie up your web request workers.
My rule for network calls is fewer and faster. Make fewer of them and/or make each one you have to do faster. If you apply fewer and faster liberally to your app, I guarantee it will decay at a slower pace and require less maintenance.
Along with making fewer and faster network calls, failing fast is important. Wrap network calls with well known resiliency patterns like circuit breakers and bulkheads. I have been working on a circuit breaker and will definitely write about it here once I have solid production usage (currently testing, post should be early 2016).
Limit Everything
Limit everything. I cannot emphasize this enough. The limits can be high, but they still need to be there. Someone someday will use your application/feature in a way you did not intend or expect. If you do not impose a limit, that someone will find that limit for you and it will most likely impact all of your customers, instead of just the one hitting the limit.
Every SELECT should have a LIMIT. Take SpeakerDeck for example. Originally, we naively showed all of a user’s presentations on their profile page. A few power users and spammers later and SpeakerDeck was hammering the database for thousands of presentations on every page load for certain users.
Every UPDATE and DELETE should have a LIMIT. Unbounded updates and deletes are a great way to cause long transactions, performance issues and replication lag. At GitHub, we have some code that handles performing this type of write in a background job in large batches (say 1k or 5k rows). Each batch is wrapped by a throttler that checks for replication lag. This allows us to perform large updates and deletes in a manner that won’t bring the database to a halt or cause our read secondaries to fall far behind.
Every message queue should have a limit. Your message queue has a limit and it is either memory, disk or CPU. You can either hit that limit and crash (fail slow), or drop data (fail fast). As bad as dropping data sounds, it is better than completely crashing. Most message queues have a way to set a limit on the number of messages to keep. Hopefully you never hit that limit, but if you do, you’ll be glad that you set it. Failing fast is always better.
Every user action should have a limit. Oof. This is a big one. We have improved on this a lot over the past year or two at GitHub, but this one still bites us in interesting ways. If you are concerned about limiting the content a user can create or something like that, at a minimum, you can set limits for what they can do in a given time period.
SpeakerDeck is once again a good example here. We limit uploads per day per user and all time per user. Users rarely hit those limits, but they help provide just enough resistance that spammers and abusers move on to easier targets.
You can also set different limits based on whether a user is using your web UI or API. API’s need higher limits, but there is a real maximum number of actions a real user can perform in a web interface in a given time frame.
Whenever possible, data should have a retention policy. This is a tough one. As developers, I think we like to keep data around forever, just in case. The truth is though, there is a lot of data that loses value over time to customers, but causes a lot of decay in a system. The decay shows up in the form of slower queries and the need for bigger hard drives. Think about which data is valuable and if there is a point in time at which that data becomes less valuable. Find ways to move less valuable data to places that will be less likely to affect decay (Another less powerful server with big disks? S3?).
An example from GitHub would be notifications that have been marked as read. We have a cron in place that uses pt-archiver to delete read notifications after a period of time. The value of a read notification decreases with time and dramatically increases the decay in our system, so we purge them.
No really, limit on every axis. Limit by rate, by size, by duration, by IP, by resource, by consumption, by concurrency and by all the aforementioned in different combinations. Limit at each layer (load balancer, application server, application, backend systems, etc.). I think you get the idea.
In Closing
By far, the two things that I have seen lead to dramatic decay in a system are network calls and lack of limits. If you remember nothing else from this post, remember to avoid network calls and limit everything.